 第439章 深度学习 大学刚毕业,你让我接手工厂?
第439章 深度学习 大学刚毕业,你让我接手工厂?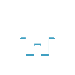 第439章 深度学习 大学刚毕业,你让我接手工厂?
第439章 深度学习 大学刚毕业,你让我接手工厂?马宇腾靠在椅背上,闭上眼睛,努力在记忆的海洋里搜寻。
没有。
什么都没有。
他感到一种久违的无力感。
这是重生以来,他第一次因为知识的壁垒而感到挫败。
就在这时,书房的门被轻轻推开。
一股淡淡的馨香飘了进来。
钟虹端著一杯热牛奶,悄无声息地走了进来。
她已经换上了家居服,长发隨意地披在肩上,身上带著沐浴后的清爽气息。
她將牛奶杯放在马宇腾手边,目光落在他面前的电脑屏幕上。
“遇到难题了?”她的声音很轻,像羽毛拂过心尖。
马宇腾睁开眼,看著妻子清澈的眼眸,点了点头,脸上带著一丝苦笑。
“在写一份技术文档,但是卡在数学推导上了。”
“哦?”钟虹的眼中掠过一丝好奇。
在她印象里,马宇腾总是无所不能的样子,这还是她第一次看到他为某个问题挠头。
她绕到书桌另一侧,身体微微前倾,看向屏幕上的內容。
“深度学习……卷积神经网络……”
她轻声念出那些標题,然后视线停留在“梯度下降”和下面那片空白区域。
“你想推导什么?”钟虹问。
马宇腾指著屏幕,將自己的困境说了出来。
“我想描述一个优化算法,用来更新神经网络的参数,让模型的预测误差最小化。我知道它的核心思想是沿著梯度下降最快的方向去调整参数,但我写不出具体的数学过程。”
他儘量用通俗的语言解释。
钟虹安静地听著,没有插话。
等马宇腾说完,她沉默了几秒,似乎在脑中构建整个数学模型。
“你的意思是,有一个包含大量参数的复杂函数,也就是误差函数。你想找到一组参数,使这个函数的值最小。”
钟虹用她自己的语言,重新定义了这个问题。
“对,就是这个意思。”马宇腾立刻点头。
“这本质上是一个多元函数求最小值的问题。”钟虹的语气平静而篤定,“用梯度下降法来解决很直观。”
她伸出纤细的手指,在空中比划著名。
“假设你的误差函数是j(θ),θ是参数向量。那么在任意一点θ,函数值下降最快的方向就是梯度的反方向,也就是-?j(θ)。”
她顿了顿,继续说道:“所以,参数的更新法则就是,用当前的参数值,减去一个很小的步长乘以梯度值。”
她隨手从笔筒里抽出一支笔,在一张空白的a4纸上,飞快地写下了一行公式:
θ_new = θ_old - α * ?j(θ_old)
“α是学习率,控制每一步更新的幅度。”她解释道。
马宇腾看著那行简洁而优美的公式,感觉堵在脑子里的那团迷雾,瞬间被一道光劈开。
就是这个!
“那……如果是一个具体的神经网络,比如逻辑回归,这个梯度该怎么算?”他追问道。
钟虹看了他一眼,没有直接回答。她坐到旁边的椅子上,將那张a4纸拉到自己面前。
本章未完,点击下一页继续阅读。(1 / 2)